Data Science Training in Psychology
 Photo by Emile Perron on Unsplash
Photo by Emile Perron on Unsplash
Psychology is generally considered a “soft” science, on the opposite end of the spectrum from the “hard” sciences of physics, chemistry, and biology. This often creates a misconception that psychology is somehow not as quantitative, computational, or rigorous, methodologically. To the contrary, psychology is in fact very “hard” (some might even say, “the hardest”). Why? Because explaining human cognition and behavior is really difficult. People do not think and behave in predictable and consistent ways like atoms and molecules.
Indeed, the combination of random variation (“noise”) in how we humans respond to our environment on an given day/hour/minute, combined with the inherent challenge of proper sampling, reliable measurement and accurate model building makes data analysis for a psychologist no easy feat. Explaining variance in psychological data has required centuries of refining statistical methods and computational tools. Fortunately, today’s scientists have access to open-source software like R and Python that have vastly enhanced our ability to work with data in a way that is more transparent and reproducible. As a result, the teaching of these tools is becoming increasingly more common in psychology graduate programs (and many other fields), particularly in statistics classes.
Graduate statistics
The Department of Psychology at the University of Oregon requires first-year graduate students to take a 3-course series of classes on statistics and data analysis. (You can access the materials for these classes here.) As I’m sure used to be the case in psychology departments across many universities, the labs for these classes were originally taught in SPSS. However, thanks to the efforts of some hard-working graduate teaching assistants who served as lab instructors at the time, the labs eventually transitioned to being taught entirely in R.
When I started TA-ing for graduate stats, we (@roseberrymaier, @flourneuro) translated the labs from SPSS to R. We created a bunch of .Rmd files for students to work from. It's so cool to see that those students are the TAs now, and they're creating these amazing materials! https://t.co/myMGefLxQX
— Dr. Jessica Kosie (@JessKosie) March 6, 2020
While learning R in first-year grad stats has immense benefits, it is also really challenging. This was certainly my experience, anyway. In addition to grappling with the dense conceptual material, learning a programming language and using it to do statistics felt really daunting since I had very little programming background before graduate school. And the reality is, given that many (myself included) tend to experience a large learning curve with programming, combined with the already hefty gradstats curriculum, there just isn’t space in these classes to teach students much beyond the basics of R.
Training needs
But the way things seem to be moving, it’s becoming more common for many students to need more general data science skills in grad school. Current psychology grad students at UO (n = 28) were recently surveyed about the degree to which they perceive they will need different data science-related skills for their desired careers and how much training in those skills is available at UO to their knowledge. Specifically, they were asked,
On a scale of 0 (“Not at all”) to 4 (“Essential”), how much do you NEED this skill for your desired career?
On a scale of 0 (“Not at all”) to 4 (“Complete”), how much training is PROVIDED in this skill at your institution?
I created the plot below (using ggplot2) to visualize how much students report they need these skills compared to how much training they feel they already have.
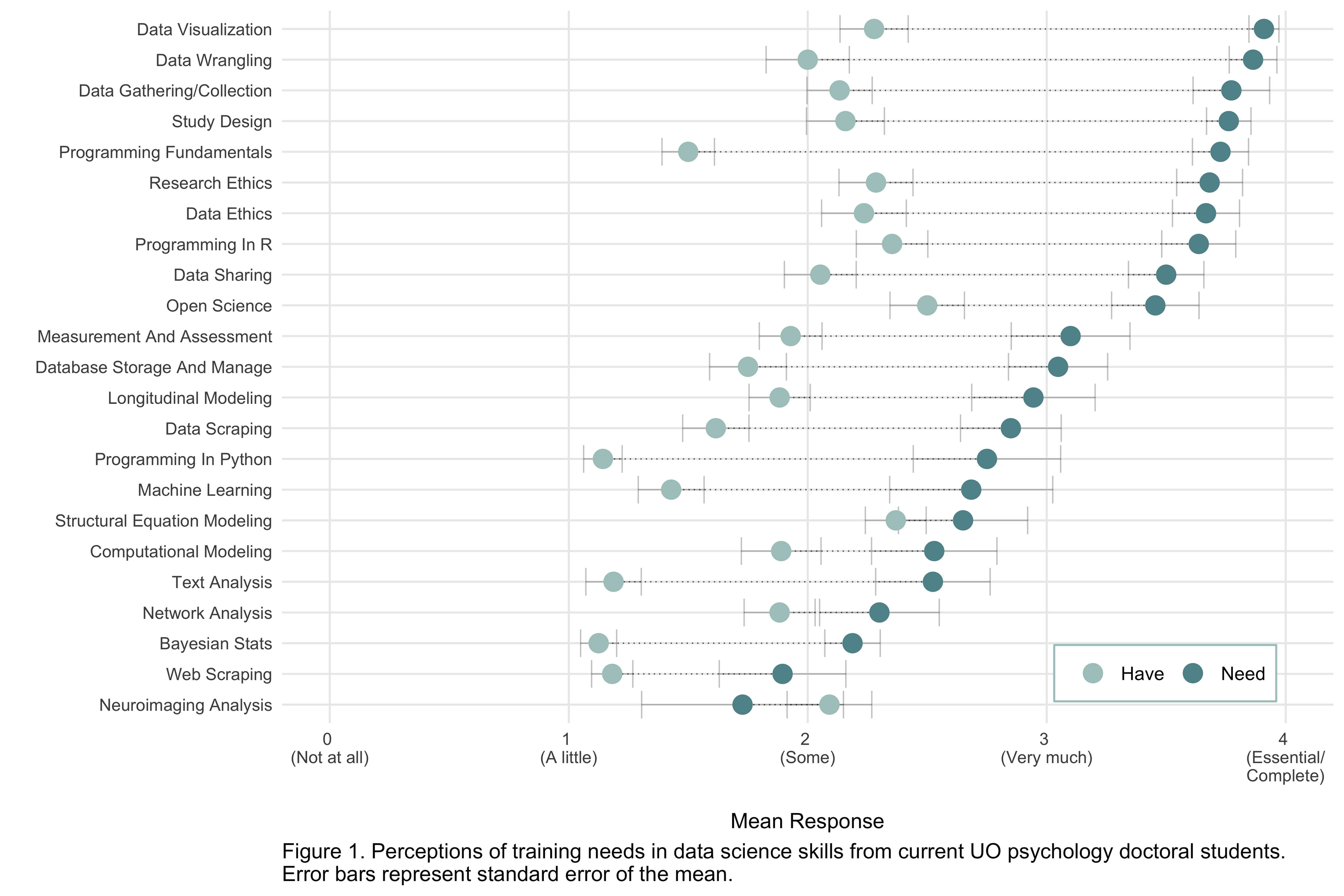
Interestingly, the top two skills that students reported needing the most on average for their careers are data visualization and data wrangling. Fortunately, this was the first year (to my knowledge) that PSY611, the first course in the gradstats sequence, included entire labs devoted to data visualization and data wrangling. More good news is that other faculty in the psych department are starting to offer courses that focus more on these skills that students seem to need the most. For example, Rob Chavez has offered a fantastic seminar called Data Science Methods in Psychology that covered a wide range of data science topics from programming in R to text processing to package creation that ultimately turned into a great collection of student-created tutorials (all of which are available here).
A collection of fantastic R tutorials from my ‘Data Science Methods in Psychology’ seminar course, created by our amazing @UOPsych grad students. https://t.co/DhBcn940uz
— Rob Chavez (@robchavez) June 12, 2018
Among other crucial research skills like study design, data collection, and research ethics, the other most coveted technical skill seems to be programming. In fact, general programming skills seems to be where there is currently the biggest gap in training in our department. The graph below shows skills ranked in descending order by how large the gap is between how much training in those skills students need and how much they currently have.
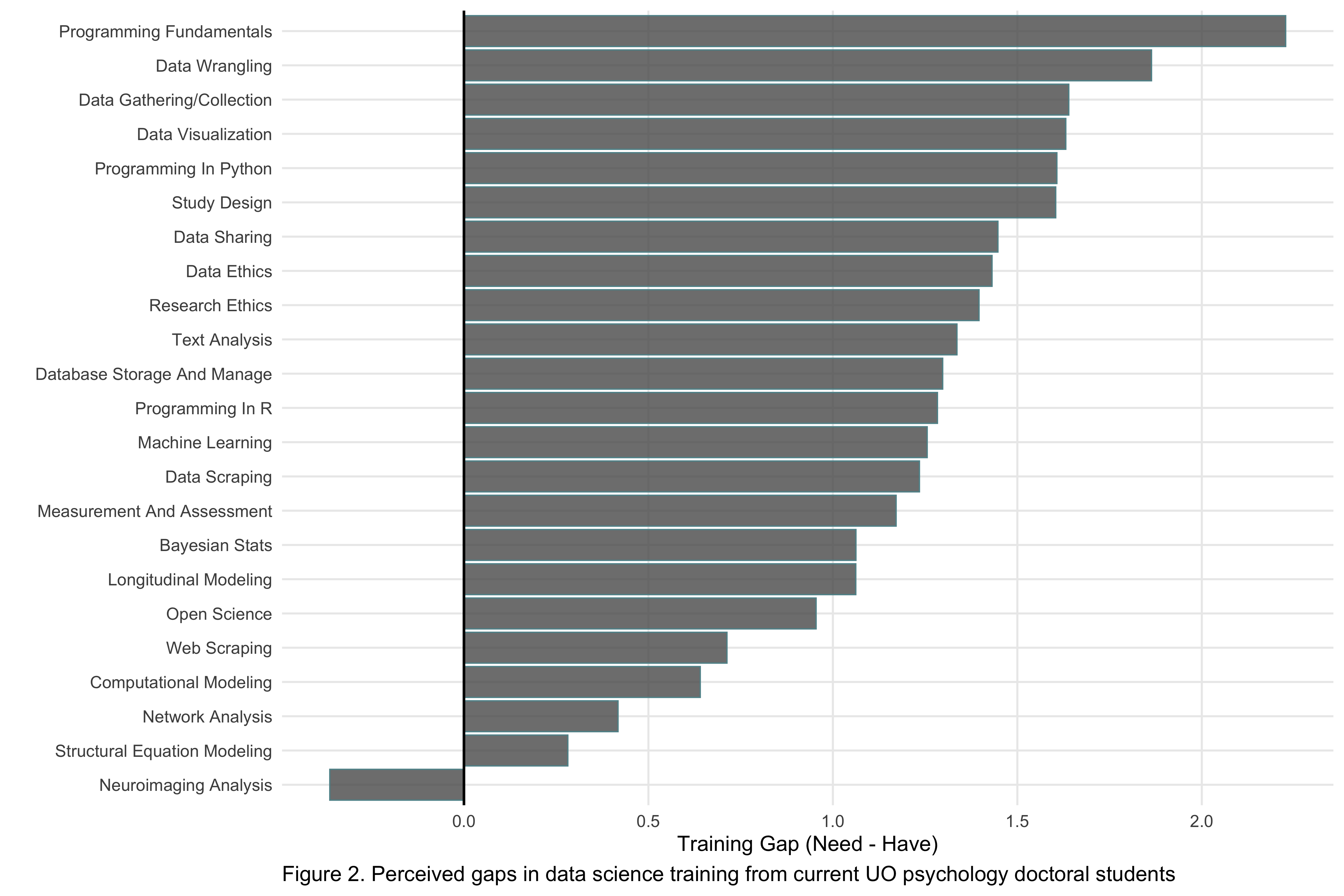
On the whole, it seems that that there are bigger training gaps for more general data science skills (e.g., programming in R and Python, data wrangling, data visualization). In contrast, the smallest gaps exist for more specialized skills like advanced statistics (e.g., computational modeling, network analysis, structural equation modeling) – likely because our department has an entire class devoted to each of these topics.
Learning Resources
So, for the most part, it seems that grad students in our department want more training in general data science skills above and beyond the training they are currently receiving through coursework. Often what this means is that grad students end up teaching themselves (and each other) these skills. Some of my peers have made really incredible tutorials on new tools and methodologies they’ve recently learned. Sometimes students also attend specialized methods workshops and take really detailed notes that could greatly benefit others who want to learn the same kind of methods. My goal is to make it easier for people (both within our department and beyond) to find these resources.
To that end, I am currently working with Sara Weston to create and curate a searchable central repository of data science resources at UO that will house such student-created tutorials, workshop notes, and other data science products (e.g. R packages, shiny apps, etc.) that other students can benefit from. We are also planning to add resources from our department’s data science and statistics classes (e.g. the gradstats sequence, multilevel modeling, network analysis, data science seminar, etc.). The hope is that making these resources easier to find and share by putting them all in one place will start to reduce some of the current gaps in data science training. The additional benefit is that students will be able to share their data science “side projects” more broadly, and it will be easier for people to know who they might be able to ask for help with learning certain topics when they need it.
This is a work in progress, so stay tuned for more details!
A final thought
Reflecting on all this has brought home a thought that I think is worth sharing. I have come to realize that, as grad students, one of the best resources we have access to during our time in grad school is each other. Personally, I have learned so much over the years from my fellow lab members. Without them, I would not have conquered my fear of Github or felt inspired to learn more about R and other programming languages. Perhaps the most impactful benefit I’ve received from them, though, is their encouragement – and that, in particular, is something I hope to pay forward as much as possible.
We all enter grad school with different backgrounds and skill sets, and in so many situations the combination of our different strengths can lead to mutual benefit. So why not help each other out?

Brendan Cullen
Doctoral Student | NSF GRFP Fellow
Psychology PhD student and aspiring data scientist studying precision medicine approaches to health behavior change.